
Artigo escrito por Henrique Branco • Desenvolvedor RPA na Cellere, com 3 anos de experiência profissional com análise e ciência de dados e automação de processos, incluindo empresas multinacionais (Bosch e ADM do Brasil).
Você que estuda e/ou trabalha com Machine Learning há algum tempo provavelmente já ouviu sobre estes termos overfitting e underfitting. Pois bem, será o tema principal deste artigo. Pretendo esclarecer de forma simples e não técnica o que são esses problemas comuns, como identificá-los e algumas sugestões para possíveis soluções.
Contextualização
Quando treinamos um modelo de Machine Learning, a idéia por trás, em termos simplificados, é que o modelo aprenda sobre os dados de entrada e possa realizar previsões, com um erro aceitável, com novos dados, que não estavam presentes nos dados de entrada, ou seja, dados nunca vistos pelo modelo.
E como avaliamos a performance de um modelo? Existem diversas métricas para as diferentes categorias de Machine Learning, que não serão abordadas à fundo, pois não é o foco do post.
Reflita comigo: você treina um modelo para que ele consiga realizar previsões quando receber novos dados, certo? Como vamos medir a performance do modelo? Podemos realizar previsões com os mesmos dados que utilizamos para treinar o modelo? Talvez o resultado seja tendencioso, pois o modelo já viu estes dados antes, durante o treinamento! Quel tal, então, entregar dados novos, nunca vistos pelo modelo? A idéia é boa, mas como saberemos se a previsão está correta ou não, se não temos o valor original da previsão para posterior comparação? Há uma solução para este impasse.
Divisão em treino e teste
Para resolver o problema mencionado acima sobre como avaliar a performance do modelo, podemos dividir os dados de entrada em 2 grupos: os dados de treino, que serão utilizados para treinar o modelo, e os dados de teste. Lembre-se que temos os valores originais dos dados de teste, que serão utilizados para verificar o erro do modelo. Assim, comparamos a previsão do modelo nos dados de teste com os valores originais. Normalmente escolhe-se 80% dos dados de entrada para treino e 20% para teste, escolhidos aleatoriamente.
Mas o que isso tem a ver com o underfitting e overfitting, afinal? Explico a seguir.
Conceito
Antes de prosseguirmos, vamos definir e conceituar o que são os termos underfitting e overfitting.
Underfitting é uma tradução para o inglês de sub-ajustado. Ou seja, nosso modelo não conseguiu aprender suficiente sobre os dados. O underfitting leva à um erro elevado tanto nos dados de treino quando nos dados de teste.
Overfitting é o oposto. O termo vem da tradução de sobre-ajustado. É quando o modelo aprende demais sobre os dados. Neste caso, o modelo mostra-se adequado apenas para os dados de treino, como se o modelo tivesse apenas decorado os dados de treino e não fosse capaz de generalizar para outros dados nunca vistos antes. Quando isso acontece, os dados de treino apresentam resultados excelentes, enquanto que a performance do modelo cai drasticamente com os dados de teste.

Como identificar?
Uma forma básica, não técnica e que não deve ser, em hipótese alguma, a única técnica a ser levada em consideração, é a visualização gráfica, conforme mostrado na imagem acima. Ela pode nos fornecer um indício de que há problemas com overfitting/underfitting. Saliento que não deve ser usada para tomar uma decisão final, apenas levantar uma suspeita a priori. E nem sempre conseguimos identificar visualmente quando esses problemas existem.
O underfitting é mais fácil de ser identificado. Ele acontece, como já mencionado previamente, quando o erro do modelo é elevado em ambos os dados de treino e teste.
Em contrapartida, o overfitting é bem mais difícil de ser perceber. Podemos identificar que há sobre-ajuste quando comparamos a performance do modelo em treino e teste, variando alguns parâmetros (como a quantidade de dados, por exemplo).
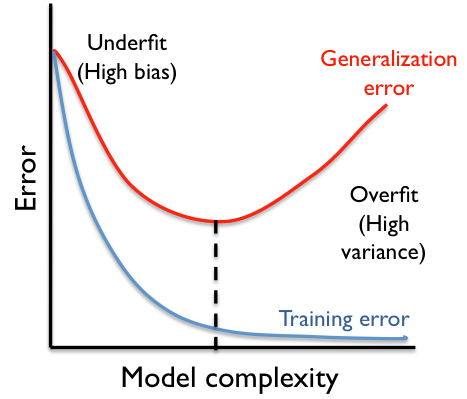
Na imagem acima, podemos considerar a complexidade do modelo como sendo a quantidade de dados, de parâmetros, ou o tipo de algoritmo utilizado. Percebam que o modelo começa com erro elevado tanto para treino quanto para teste. Nesta etapa da curva há o underfitting.
Conforme aumentamos a complexidade do modelo, ele vai se ajustado aos dados de treino e teste até um determinado ponto. A partir deste ponto, que é o ponto ótimo, o erro para os dados de teste comçeam a subir novamente e o mesmo erro continua decaindo para os dados de treino. Neste ponto, a partir desta diferença dos erros de treino e teste, podemos afirmar que o modelo sofre overfitting.
Causas e soluções
O overfitting tem algumas causas principais, que podem direcionar a solução do problema:
- Algoritmo muito complexo para os dados: podemos simplificar nosso modelo escolhendo um algoritmo mais simples, com menos parâmetros, caso seja possível. Isso reduz as chances do modelo sofrer overfitting.
- Poucos dados de treinamento: talvez seja necessário coletar mais dados para treinar o modelo.
- Ruídos nos dados de treinamento: Caso exista algum tipo de ruído (valores extremos ou até mesmo valores incorretos nos dados), pode ser que o modelo aprenda sobre ele, levando ao overfitting. Caberia um pré-processamento adequado para tratar essa interferência.
Porém, se formos muito rígidos nos tratamentos acima, podemos ir para o outro extremo, o underfitting.
- Algoritmo inadequado, pouco poderoso para os dados: aqui podemos amplificar o poder do nosso algoritmo escolhendo outro com mais parâmetros para solucionar o underfitting.
- Características não representativas: neste caso, pode ser que as características que estamos utilizando para treinar o modelo não sejam representativas (não tenham relação entre si ou não sejam importantes para o modelo).
- Modelo com muitos parâmetros de restrição: o modelo torna-se inflexível, restrito, e não consegue se ajustar de forma adequada aos dados.
Conclusão
Neste post abordamos sobre overfitting e underfitting, problemas comuns da área de ciência de dados. A partir da contextualização, expliquei o porque dividimos os dados em treino e teste, e como validamos o modelo. Definimos, então, os conceitos dos problemas tema do artigo, como identificá-los e as possíveis causas e soluções.
Tudo de uma forma simples e não técnica para facilitar a leitura! Espero ter contribuido de alguma forma para seu crescimento. Obrigado!
Contatos
Gostou desse post? Aprendeu um pouco mais sobre underfitting e overfitting? Gostaria de entrar em contato comigo para troca de experiência e discussões posteriores? Clique nos ícones abaixo e me envie uma mensagem!