— Brasil
Migração On-premise para Cloud Services
Atualmente existe uma tendência de migração de dados da arquitetura “on-premise” ou conhecida como cliente-servidor para o ambiente “Cloud” em português “Nuvem”.
Este tipo de migração tem ocorrido devido a dois fatores básicos:
- O custo dos serviços em nuvem vem se popularizando e reduzindo devido a maior concorrência;
- A segurança e privacidade de dados na nuvem vem se consolidando no mercado e isso traz às grandes corporações mais tranquilidade no uso dessa nova tecnologia;
Porém, o processo de migração ainda não é tão fácil e transparente como nos fazem crer os provedores de serviços.
O fato é que antes de migrar, existem etapas a serem cumpridas para que o processo de migração seja assim tão simples quanto do ponto de vista do provedor de serviços cloud.
Neste artigo vou fazer um paralelo com um caso real de migração de uma indústria que buscava migrar essencialmente sua solução de ERP – CRM para o ambiente de nuvem para criar um “Data lake” com informações em “real-time” para área de vendas e logística.
Neste caso em especifico o cliente já tinha clara a sua intenção para o processo de migração, o que nem sempre ocorre na maioria das empresas. Muitas desejam migrar todo ambiente de dados de uma só vez e sai fazendo cotação de provedor sem sequer saber o volume real de dados que deseja migrar e nem o que fará com eles na nuvem.
Utilizando o caso real deste cliente vou listar a seguir os passos corretos para um projeto de migração de dados para ambiente nuvem de sucesso:
Passo 1 – Diagnóstico de negócios
A fase de diagnóstico do negócio é para entender a razão pela qual a empresa deseja fazer a migração de dados para o ambiente de nuvem. É para reduzir custos? Melhorar a qualidade do atendimento ao cliente/usuário final? O volume de dados armazenados tem crescido exponencialmente? Possui uma estratégia “data-driven”? Esta em quê fase de maturidade em termos de transformação digital?
Tudo isso é muito relevante para que possamos escolher as ferramentas mais adequadas para cada tipo de negócio e cada fase de maturidade da empresa na utilização dos dados para estratégia de negócios. Só assim será possível dimensionar o retorno sobre o investimento.
Passo 2 – Levantamento de Processos
Uma vez que identifiquemos o propósito da migração, vamos ter que identificar os processos que envolvem esta necessidade de negócios. Utilizando aqui o exemplo da empresa que comentei, o foco dela era otimizar o processo de vendas e entregas dos seus produtos. A empresa atende a várias redes varejistas no Brasil todo e possui representantes de vendas distribuídos pelo país todo. Os representantes colocam seus pedidos no sistema de ERP/CRM da empresa e através deste sistema é que todo o processo produtivo e de logística são alimentados.
No caso da empresa em questão, a dificuldade estava em manter os distribuidores atualizados quanto ao processo de fabricação e entrega dos produtos por eles comercializados e também avaliar as empresas prestadoras de serviços de logística, mediante a comprovação da entrega ao cliente final.
Com os processos de atualização de dados todos rodando em “batch”, ou seja, os processos eram atualizados apenas a noite e os sistemas apresentavam os dados sempre em D+1 após as 12:00 horas.
Neste intervalo diversas vezes, mercadorias foram extraviadas, clientes reclamavam de não receber o que no sistema aparecia como entregue e as reclamações se acumulavam tanto por parte dos representantes quanto dos clientes finais.
Por isso a revisão do processo de inserção dos dados no sistema de vendas (ERP/CRM) e as interfaces do mesmo com os sistemas de linha de produção e logística foram revisados. Algumas etapas de autorizações de acesso e validações de dados foram reorganizadas.
Passo 3 – Diagnóstico das Bases de Dados atuais
O diagnóstico das bases atuais quase sempre é a etapa mais complexa. Na maioria das vezes estas não tem uma documentação atualizada e precisamos manipulá-las e fazer entrevistas com as pessoas que se utilizam delas para realmente obter seu modelo de dados e refazer a documentação, elaborar um catálogo de dados, mapear interdependências e possíveis inconsistências no processo de coleta, tratamento e atualização dos dados.
Passo 4 – Redesenhar processos a serem otimizados
Uma vez que temos os processos atuais bem definidos, a documentação das bases atualizadas, podemos então desenhar a nova arquitetura de dados prevendo os processos otimizados.
Passo 5 – Avaliação de ferramentas (Cloud, ETL, APIs, etc)
Uma vez que temos a arquitetura ideal planejada, vamos precisar avaliar as ferramentas de mercado disponíveis para atender às características de negócios do processo que desenhamos.
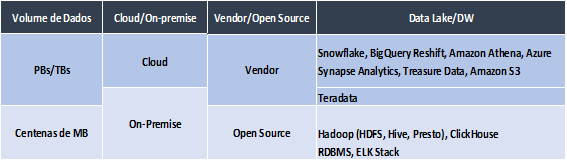
Segue aqui uma tabela simples com critérios básicos a serem considerados na escolha das ferramentas:
– Devem ser considerados o volume de dados, o ambiente atual, se desejamos ter uma solução “open source” ou “proprietária”.
Listamos aqui algumas sugestões levando em conta estes critérios.
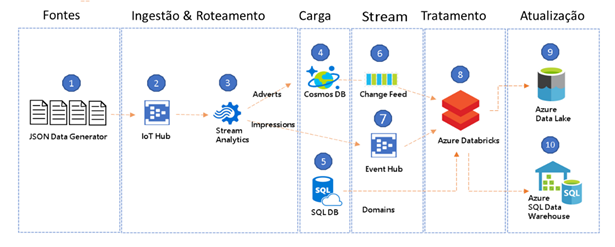
Passo 6 – Desenho da arquitetura
Uma vez que tenhamos selecionado as ferramentas de acordo com as necessidades do cliente, vamos a elaboração da arquitetura, planejada:

Os dados originados do aplicativo móvel dos representantes e fornecedores logísticos passaram a ser agregados aos dados dos sistemas de ERP/CRM e de ERP/Produção & Logística
Passo 7 – Validação da arquitetura
O processo de validação é necessário para que possamos confirmar a performance não só do ambiente tecnológico como também as alterações processuais que fizemos para que a nova arquitetura pudesse ser desenhada.
Nesta etapa trabalhamos com uma amostragem do que seria o processo real de ponta a ponta.
Em um ambiente controlado (de testes ou homologação) vamos tentar replicar as circunstâncias reais. No caso do meu cliente havíamos optado pelo a MS/Azure e o ambiente de testes ficou assim:

Passo 8 – Migração
Após a validação nos testes quanto a performance da solução em termos de tempo de atualização, tratamento dos dados e toda orquestração até a atualização final, partimos para a migração por etapas.
As etapas foram definidas de acordo com um mapa de riscos de processo elaborado a várias mãos. Contamos com a área de governança de dados da empresa, as áreas clientes e o novo provedor de serviços de nuvem para avaliarmos os riscos da migração e ponderarmos quanto às datas e horários, bem como os critérios de validação e monitoramento após migração.
Nesta etapa trabalhamos com uma instancia monitorada para inicio da migração conforme esquema abaixo:

Passo 9 – Operação assistida
O processo de migração através da criação de instancias na nuvem que replicavam o ambiente on-Premise foi executado com espaçamento de 7 dias entre cada nova base migrada. Ao final, quando a nuvem refletia 100% do ambiente on-premise iniciamos o processo de operação assistida.
A operação assistida nada mais é que a checagem dos indicadores calculados no ambiente on-premise versus o ambiente nuvem para que pudéssemos ter a certeza de que todas as APIs e ETLs criadas dentro do novo processo de atualização de dados estavam corretas e refletindo a realidade.
Passo 10 – Entrar em produção
O último passo é realmente virar a chave, abandonar o processo on-premise e manter apenas o ambiente em nuvem como válido.
Esse projeto durou 6 meses em um ambiente com 6 bases de dados diferentes totalizando em torno de 19PB de dados armazenados.
O que vemos usualmente são aqueles planos de projeto que dão 3 meses para migrar 10MB de dados ou 20TB de dados. Como podem ver neste exemplo, não é bem assim.
Para que tudo ocorresse dentro do prazo estipulado e com sucesso, envolvemos uma equipe de:
- 1 arquiteto de dados sênior 30% dedicado ao projeto;
- 2 engenheiros de dados, sendo 1 sênior e um júnior 100% dedicados ao projeto;
- 1 SCRUM master fazendo a gestão do projeto e interlocução com as diversas áreas envolvidas dedicado 50% ao projeto;
- O head de Analytics da empresa 30% dedicado ao projeto;
A experiencia, maturidade e dedicação dos profissionais envolvidos fazem a maior diferença para o sucesso de um projeto de migração de dados. A metodologia ágil corrobora para que os envolvidos realmente se envolvam diariamente no andamento do projeto, com isso todos ganham no final.
Fontes:
Microsoft Migration Assistance – https://docs.microsoft.com/pt-br/sql/dma/dma-overview?view=sql-server-ver15
A autora:
- Especialização em Gestão de Dados (CDO Foundations) pelo MIT – Massachusetts Institute of Technology – EUA;
- Mestrado em Adm. Empresas pela FGV e Graduada em Adm. Empresas pela FAAP;
- Empreendedora na Consultoria estratégica Analytics Data Services;
- Embaixadora da Stanford University para o projeto Women In Data Science – WIDS;
- Voluntária Grupo Mulheres do Brasil;
- Professora Universitária, no SENAC para os cursos de Pós-Graduação em BIG Data e Analytics e para os cursos de graduação a Distância do SENAC;
- Autora dos livros:
- A Atuação do Profissional de Inteligência Competitiva, Publicit, 2015
- Pesquisa de Marketing, Série Universitária, SENAC, 2017
- Liderança/Participação em Comunidades Digitais: Women In Blockchain, ABINC Data & Analytics, FINTECHs & Newtechs, Marco Civil IA
- Atuação como executiva nas áreas de planejamento estratégico de marketing, gestão e governança de dados em empresas como Unisys, Teradata, Santander, IBM dentre outras


