Introdução a Redes Neurais Convolucionais e Classificação de Imagens
Nos últimos anos, as Redes Neurais Convolucionais (CNNs) revolucionaram o campo da visão computacional, oferecendo resultados excepcionais em tarefas como classificação de imagens, detecção de objetos e reconhecimento facial. Esta introdução visa fornecer uma visão geral de como as CNNs funcionam, destacando seu papel crucial na classificação de imagens.
O que são Redes Neurais Convolucionais?
As Redes Neurais Convolucionais (CNNs) são um tipo específico de rede neural projetada para processar dados que têm uma estrutura semelhante à de uma grade, como imagens. Diferente das redes neurais tradicionais, que tratam cada pixel de uma imagem de forma independente, as CNNs exploram a relação espacial entre os pixels, tornando-as ideais para tarefas de visão computacional.
A estrutura básica de uma CNN inclui camadas convolucionais, camadas de pooling (ou sub-amostragem) e camadas totalmente conectadas. Essa arquitetura permite que a rede capture informações tanto locais quanto globais da imagem, levando a uma análise mais precisa e robusta.
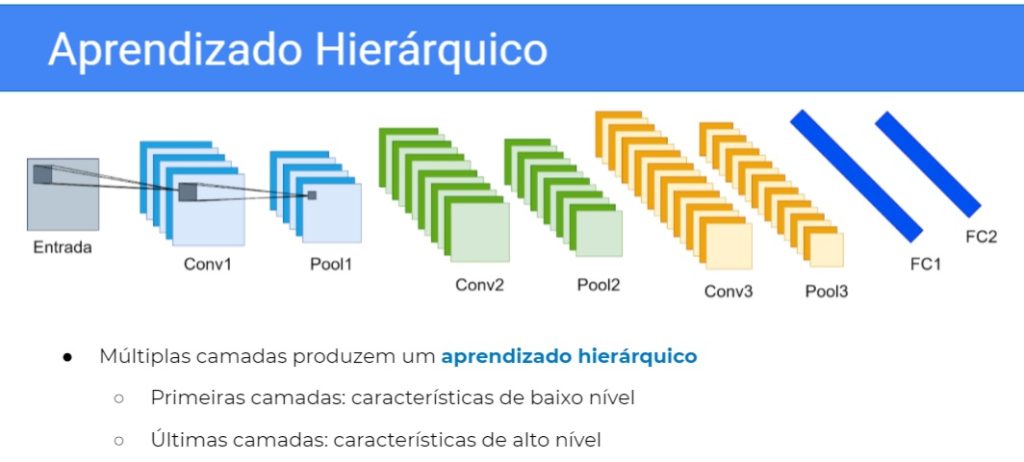
Como as CNNs Funcionam?
1. Camada Convolucional
A camada convolucional é a base das CNNs. Nessa camada, são aplicados filtros (ou kernels) sobre a imagem de entrada. Esses filtros percorrem a imagem, gerando um mapa de ativação que representa diferentes características da imagem original, como bordas, texturas e padrões.
- Filtros: São pequenas matrizes de pesos que percorrem a imagem em regiões específicas. Um filtro pode detectar características como bordas verticais ou horizontais, enquanto outro pode identificar padrões complexos.
- Mapas de Características: Cada filtro gera um mapa de características, que é essencialmente uma versão da imagem onde apenas certos aspectos (por exemplo, bordas) foram extraídos. Esses mapas são usados como entrada para a próxima camada convolucional.
2. Camada de Pooling
Após a convolução, a camada de pooling reduz a dimensionalidade dos mapas de características. A forma mais comum é o max pooling, onde o maior valor em uma determinada região é retido. Isso reduz o tamanho dos dados, mantendo informações relevantes e acelerando o processamento.
- Objetivo: A redução de dimensionalidade realizada pela camada de pooling não só melhora a eficiência computacional, mas também ajuda a rede a ser mais robusta a pequenas variações e distorções na imagem.
3. Camadas Totalmente Conectadas
Depois que as imagens foram transformadas por várias camadas convolucionais e de pooling, elas passam por camadas totalmente conectadas, onde todos os neurônios de uma camada estão conectados a todos os neurônios da camada seguinte.
- Classificação: A última camada totalmente conectada produz a saída final, que é uma distribuição de probabilidade sobre as classes possíveis. A classe com a maior probabilidade é então considerada a previsão final do modelo para a imagem.
Fluxo Geral do Treinamento e Inferência
- Pré-processamento: Antes de alimentar as imagens na CNN, é comum realizar algum tipo de pré-processamento, como redimensionamento, normalização e, em alguns casos, aumento de dados (data augmentation) para expandir o conjunto de dados de treinamento.
- Treinamento: Durante o treinamento, a rede ajusta os pesos dos filtros de forma a minimizar o erro de previsão. O objetivo é que a rede aprenda a extrair as características mais relevantes para distinguir entre as classes de imagens.
- Inferência: Após o treinamento, a rede pode ser usada para classificar novas imagens. Durante a inferência, a imagem passa pelas mesmas camadas convolucionais, de pooling e totalmente conectadas, e o resultado final é uma classificação com base nas características extraídas.
Aplicações de CNNs na Classificação de Imagens
As CNNs se destacaram em uma variedade de tarefas de classificação de imagens, incluindo:
- Reconhecimento de Objetos: Identificação de objetos em imagens, como animais, veículos ou pessoas.
- Reconhecimento Facial: Uso de CNNs para identificar e verificar rostos em imagens ou vídeos.
- Diagnóstico Médico: Análise de imagens médicas, como raios-X, para detectar doenças ou condições.
- Visão em Veículos Autônomos: Classificação e detecção de objetos para navegação e tomada de decisão em veículos autônomos.
Desafios e Considerações no Uso de CNNs
Embora as CNNs ofereçam vantagens significativas, elas também apresentam desafios:
- Requisitos Computacionais: O treinamento de CNNs pode ser intensivo em termos de processamento e memória, especialmente para grandes conjuntos de dados.
- Overfitting: Se a rede for muito complexa, ela pode se ajustar excessivamente ao conjunto de treinamento, resultando em um desempenho ruim em dados não vistos.
- Interpretação: CNNs são muitas vezes tratadas como “caixas-pretas”, o que pode dificultar a interpretação de suas previsões e decisões.
Ferramentas e Frameworks para Implementação de CNNs
Existem diversos frameworks que facilitam a implementação de CNNs, incluindo:
- TensorFlow: Uma biblioteca de aprendizado de máquina popular, com suporte extensivo para deep learning e visão computacional.
- PyTorch: Uma biblioteca de deep learning que é particularmente popular em pesquisa devido à sua flexibilidade e facilidade de uso.
- Keras: Uma API de alto nível construída sobre o TensorFlow que torna a construção de redes neurais acessível e intuitiva.
Conclusão
Redes Neurais Convolucionais revolucionaram o campo da visão computacional e estão na vanguarda de muitas das inovações que vemos hoje em reconhecimento de imagem e classificação. Embora possuam complexidade e requeiram poder computacional, suas aplicações e eficácia tornaram-se indispensáveis para uma vasta gama de setores. Entender a estrutura básica das CNNs e seu processo de classificação de imagens é o primeiro passo para explorar esse campo em constante evolução.