
Artigo escrito pela professora Janete Ribeiro
O que é ETL – etapa de coleta, ingestão e tratamento de dados.
Tenho percebido que existe uma grande dificuldade no aprendizado das técnicas de análise de dados a etapa de coleta, ingestão e tratamento de dados.
Esta fase que é a origem do “insight” tão desejado, ou da resposta da “Inteligência Artificial”, tão admirada, muitas vezes não é executada com o devido cuidado, podendo assim arruinar o resultado tão esperado.
Passo a passo para cientistas de dados
Vou tentar ser bem didática quanto aos passos para que qualquer “Cientista de Dados” aspirante possa ter a sua primeira análise exploratória de dados bem sucedida:
RAW DATA
Tudo começa com o RAW DATA — Dado bruto, ou seja, exatamente como foi extraído do sistema origem, ou capturado na internet. Características do banco de dados em estado bruto (RAW Data) — muito grande, muito distribuído (processamento clusterizado), muitos atributos categóricos, relacionamentos multivariados, dados pessoais, valores em branco, valores inválidos ou muito discrepantes. Para “tratar” estes dados e transformá-los em “dados consumíveis”, precisamos ter em mente o seguinte:
Dados não estruturados
0. Arquivo muito grande, normalmente são dados não estruturados, como streeming, dados de equipamentos inteligentes (IoTs), que geram listas gigantescas online e real-time. Para resolver este primeiro impasse da “ingestão de dados”, a primeira solução é particionar. Ou seja fazer a carga em partes ou se o sua infraestrutura permitir, adotar arquitetura de micro serviços. Assim você ganhará “escalabilidade”. Eis a primeira palavra chave do processo de ingestão, tornar esse processo “escalável” e “automatizado”, para que após a implementação da solução como um todo, você não tenha que repetir o sofrimento diariamente.
O que é preciso fazer?
1. Para iniciar o processo de tratamento é preciso tentar reduzir a quantidade de atributos que possam complicar o processo de análise. Um exemplo, se em um banco de dados você tem a data de nascimento de cada usuário, e o processo de análise demanda segmentar pessoas por faixa etária, o ideal é que você faça esse calculo previamente, para que algoritmo que será utilizado depois não tenha que calcular linha por linha. Isso consumiria dias de processamento, caro e prejudicial ao resultado da análise. Então esta é a etapa de identificar quais são as variáveis que podemos calcular, agrupar com vistas ao estudo final.
2. Então partimos para análise univariada, que nada mais é do que identificar a chave ou atributo comum que podemos utilizar para extrair características do foco da análise. Por exemplo, se estamos fazendo um estudo de perfil do cliente, devemos buscar alguma identificação de cliente nas diversas tabelas do dado bruto, para poder reunir todos atributos relacionados ao cliente.
Análise Multivariada
3. Uma vez detectado o atributo ou a chave única que liga as características do foco do estudo, vamos fazer a análise bi ou multivariada, para identificar quais atributos tem maior peso em relação ao nosso alvo e as correlações entre estes atributos;
4. Agora faremos a análise descritiva, ou seja, através de um método estatístico de análise descritiva, você obterá a frequência de cada registro no banco de dados, com esta informação será possível avaliar se o conteúdo do banco de dados possui o volume necessário de informações válidas. Esta etapa vai lhe permitir saber se você precisa coletar mais dados para por exemplo suprir uma necessidade de informação quanto a algum atributo.
5. Agora vamos fazer mais uma análise para detectar se há algum item que pode provocar um fator isolado (outlier) que inviabilizaria o propósito do estudo. Por exemplo, se você estava fazendo um estudo sobre viagens de Brasileiros para Europa no período de março à junho, o ano de 2020 será um “outlier”, pois nele ocorreu um evento totalmente atípico, uma pandemia bem neste período, impedindo que as pessoas viajassem.
6. Por fim vamos fazer o “saneamento” dos dados, isto ajustar todos os registros em um formato que seja padrão (tamanho, tipo de campos), ou seja, vamos normalizar os dados e documentar para que estes possam ser consumidos pelos modelos estatísticos (machine learning) que farão o estudo almejado.
Representação gráfica do processo
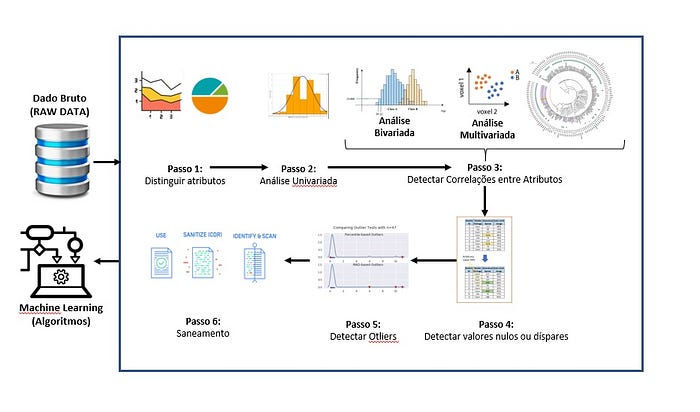
Cada uma das etapas demanda conhecimentos em programação, como “R”, “Phyton”, “SQL” ou o domínio de ferramentas pré-prontas para manipulação de dados, como Talend, Alteryx dentre outras e as bibliotecas do ecossistema Hadoop.
Como podem ver, a etapa de “Ingestão” e “Tratamento de Dados” em um projeto de BIG Data e Analytics é muito importante e cheia de detalhes. Quanto mais atenção você investir nesta etapa, melhores serão os resultados obtidos na próxima etapa, a do desenvolvimento e aplicação de modelos estatísticos (Modelagem e Avaliação).
Mas falaremos desta outra etapa no próximo artigo.
Fonte: A comprehensive review of tools for exploratory analysis of tabular industrial datasets Aindrila Ghosha,Mona Nashaata, James Millera, Shaikh Quaderb, Chad Marstonca Department of Electrical and Computer Engineering, University of Alberta Canada
(PDF) A comprehensive review of tools for exploratory analysis of tabular industrial datasets. Available from: https://www.researchgate.net/publication/329930775_A_comprehensive_review_of_tools_for_exploratory_analysis_of_tabular_industrial_datasets [accessed May 20 2020].
A autora:
- · Embaixadora da Stanford University para o projeto Women In Data Science — WIDS;
- · Voluntária Grupo Mulheres do Brasil;
- · Especialização em Gestão de Dados (CDO Foundations) pelo MIT — Massachusetts Institute of Technology — EUA;
- · Mestrado em Adm. Empresas pela FGV;
- · Graduada em Adm. Empresas pela FAAP;
- · Professora Universitária no SENAC para os cursos de Pós-Graduação em BIG Data e Gestão do Conhecimento e Inovação e para os cursos de graduação a Distancia do SENAC;
- · Autora dos livros:
- · A Atuação do Profissional de Inteligência Competitiva, Publicit, 2015
- · Pesquisa de Marketing, Série Universitária, SENAC, 2017
- · Liderança/Participação em Comunidades Digitais: Women In Blockchain, ABINC Data & Analytics, FINTECHs & Newtechs, Marco Civil IA
- · Empreendedora na Consultoria estratégica Analytics Data Services;
- · Atuação como executiva nas áreas de planejamento estratégico de marketing e gestão e governança de dados em empresas como Unisys, Teradata, Santander, IBM dentre outras
3 comentários
Muito bom esse passo a passo ! Excelente !!!