

Informações das Features da Base de dados do Spotify: https://developer.spotify.com/web-api/get-audio-features/
Análise Exploratória
Importação das bibliotecas utilizadas:
#Importação das bibliotecas a ser utilizadas:
from sklearn.model_selection import cross_val_predict
from sklearn import metrics
import matplotlib.pyplot as plt
import pandas as pd
import numpy as np
from sklearn import svm
import seaborn as sns
import warnings
from scipy import stats
warnings.simplefilter(action='ignore', category=FutureWarning)
warnings.simplefilter(action='ignore', category=RuntimeWarning)Leitura do arquivo csv e criação do DataFrame Pandas:
# Obtendo dados de músicas do spotify
dataset = pd.read_csv('databases/spotify_data.csv', sep=',')Vamos ver como está apresentado nosso dataset observando somente as colunas numéricas que serão mais relevantes a análise:
dataset.describe()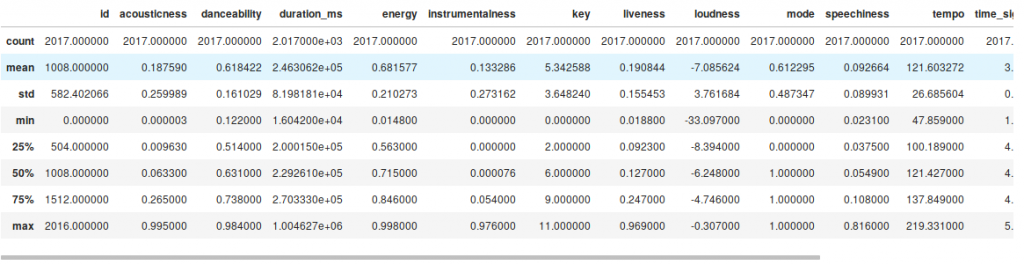
Entendendo um pouco dos conceitos do dataset
Após verificar que há alguns conceitos desconhecidos como acousticness e danceability presentes no dataset, acessei o site de referência sobre a base de dados do Spotify e achei melhor acrescentar essas informações no artigo, com a finalidade de facilitar o entendimento da visualização dos dados a ser realizada futuramente:
Acousticness: Uma medida de confiança de 0.0 a 1.0 para definir se a faixa é acústica,ou seja, utiliza equipamentos sem meios eletrônicos. Faixas com o valor 1.0 possuem alta confiança que sejam acústicas.
Danceability: Classifica como uma faixa é adequada para dançar baseada em uma combinação de elementos musicais, incluindo tempo, estabilidade de ritmo, força de batida e regularidade geral. Um valor de 0.0 significa que a faixa possui uma tendência de ser menos dançante e 1.0 indica uma grande tendência de ser dançante.
Energy: A Energia é medida de 0.0 a 1.0 e representa uma medida perceptual de intensidade e atividade. Normalmente, faixas energéticas são rápidas e barulhentas. Em resumo, um valor de energia 0.0 significa que a faixa possui uma tendência de ser mais “calma”, como uma música clássica e 1.0 indica uma grande tendência de ser músicas mais agitadas como o death metal.
Instrumentalness: Prevê se uma faixa não contém vocais. Os sons “Ooh” e “aah” são tratados como instrumentais neste contexto. Faixas de rap ou palavras faladas são claramente “vocais”. Quanto mais próximo o valor de instrumentalness for de 1.0, maior a probabilidade de a faixa não conter conteúdo vocal. Valores acima de 0.5 destinam-se a representar faixas instrumentais, mas a confiança é maior à medida que o valor se aproxima de 1.0
Liveness: Detecta a presença de um público na gravação. Valores mais altos de atividade representam uma probabilidade maior de que a faixa foi executada ao vivo. Um valor acima de 0.8 fornece uma forte probabilidade de que a faixa seja ao vivo.
Loudness: O volume total de uma faixa em decibéis (dB). Os valores de sonoridade são calculados ao longo de toda a faixa e são úteis para comparar a intensidade relativa das faixas. A sonoridade é a qualidade de um som que é o principal correlato psicológico da força física (amplitude). Valores típicos variam entre -60 e 0 db.
Speechiness: Speechiness detecta a presença de palavras faladas em uma faixa. Quanto mais exclusivamente discursiva a gravação (por exemplo, talk show, audiobook, poesia), mais próximo de 1.0 o valor do atributo. Valores acima de 0.66 descrevem faixas que provavelmente são feitas inteiramente de palavras faladas. Valores entre 0.33 e 0.66 descrevem faixas que podem conter música e fala, seja em seções ou em camadas, incluindo casos como o rap. Valores abaixo de 0.33 provavelmente representam músicas e outras faixas não relacionadas à fala.
Valence: Uma medida de 0.0 a 1.0 descrevendo a positividade musical transmitida por uma faixa. Faixas com alta valência (mais próximas de 1.0) soam mais positivas (por exemplo, felizes, alegres, eufóricas), enquanto as faixas com baixa valência soam mais negativas (por exemplo, triste, deprimido, zangado).
Tempo: O tempo total estimado de uma faixa em batidas por minuto (BPM). Na terminologia musical, tempo é a velocidade ou ritmo de uma determinada peça e deriva diretamente da duração média da batida.
Após conhecer os conceitos a serem trabalhados, vamos visualizar a dispersão desses dados:
# Função para plotagem dos gráficos de dispersão
def plotarDispersoes(axis,features,colors, titles):
fig, (axis) = plt.subplots(ncols=len(axis), figsize=(20, 5))
qtd_itens = len(axis)
i = 0
while i < qtd_itens:
axis[i].hist(dataset[features[i]], 10, density=True, histtype='stepfilled', facecolor=colors[i], alpha=0.75)
axis[i].set_title(titles[i])
i+=1
fig.tight_layout()
plt.show()Criação do primeiro painel com os gráficos de dispersão de Acousticness, Danceability, Energy e Instrumentalness:
# Configuração do primeiro panel de gráficos de dispersão
axis = ['ax0','ax1','ax2','ax3']
features = ['acousticness', 'danceability', 'energy', 'instrumentalness']
colors = ['red', 'blue','#42f465', '#f4b342']
titles = ['Acousticness', 'Danceability', 'Energy', 'Instrumentalness']
plotarDispersoes(axis,features,colors,titles)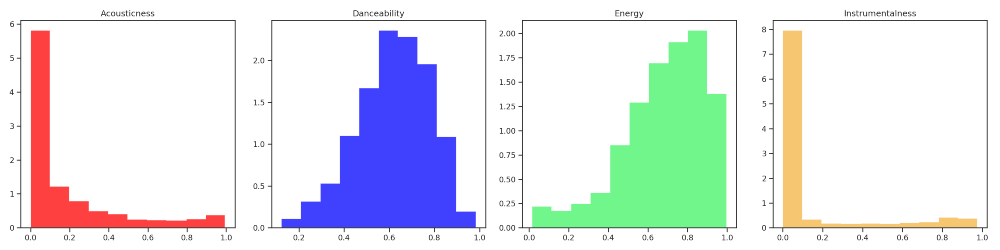
Criação do segundo painel com os gráficos de dispersão de Liveness, Loudness, Speechiness, Valence e Tempo:
# Configuração do segundo painel de gráficos de dispersão
axis = ['ax0','ax1','ax2','ax3','ax4']
features = ['liveness', 'loudness', 'speechiness', 'valence', 'tempo']
colors = ['#bc0f37', '#a6caed','#d66262', '#f4b342', '#2a4f48']
titles = ['Liveness', 'Loudness', 'Speechiness', 'Valence', 'Tempo']
plotarDispersoes(axis,features,colors,titles)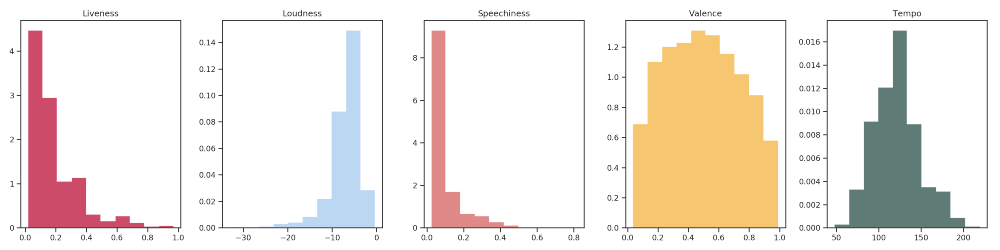
Correlação dos Dados
Primeiro vamos entender o que significa o termo correlação: A correlação entre duas variáveis ou features ocorre por exemplo quando ao alterar o valor de uma, o valor da outra também é alterado. Essa relação pode ocorrer de forma mais forte (grandes alterações) ou mais leve (alterações quase imperceptíveis) e de formas positivas ou negativas.
Correlação positiva: Indica que as duas variáveis se movem juntas, e a relação é mais forte quanto mais a correlação se aproxima de um.
Correlação negativa: Indica que as duas variáveis movem-se em direções opostas, e que a relação também fica mais forte quanto mais próxima de menos 1 a correlação ficar.
Agora que revisamos sobre a correlação, podemos nos orientar por essa tabela para avaliar as correlações desse dataset, tanto para valores positivos quanto para negativos:

Vamos então observar inicialmente qual a correlação entre as colunas desse dataset:
dataset.corr()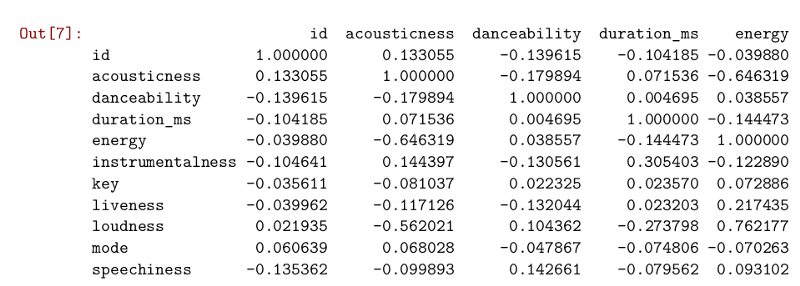
Para ter uma visualização mais interessante desses dados, vamos visualizar essa correlação através de um heatmap (mapa de calor):
%matplotlib inline
plt.figure(figsize=(12,12))
sns.heatmap(dataset.corr(), annot=True, linewidths=0.5, linecolor='black', cmap='inferno')
plt.xticks(rotation=90)
plt.savefig("imagens/heatmap.png", dpi=150)
plt.show()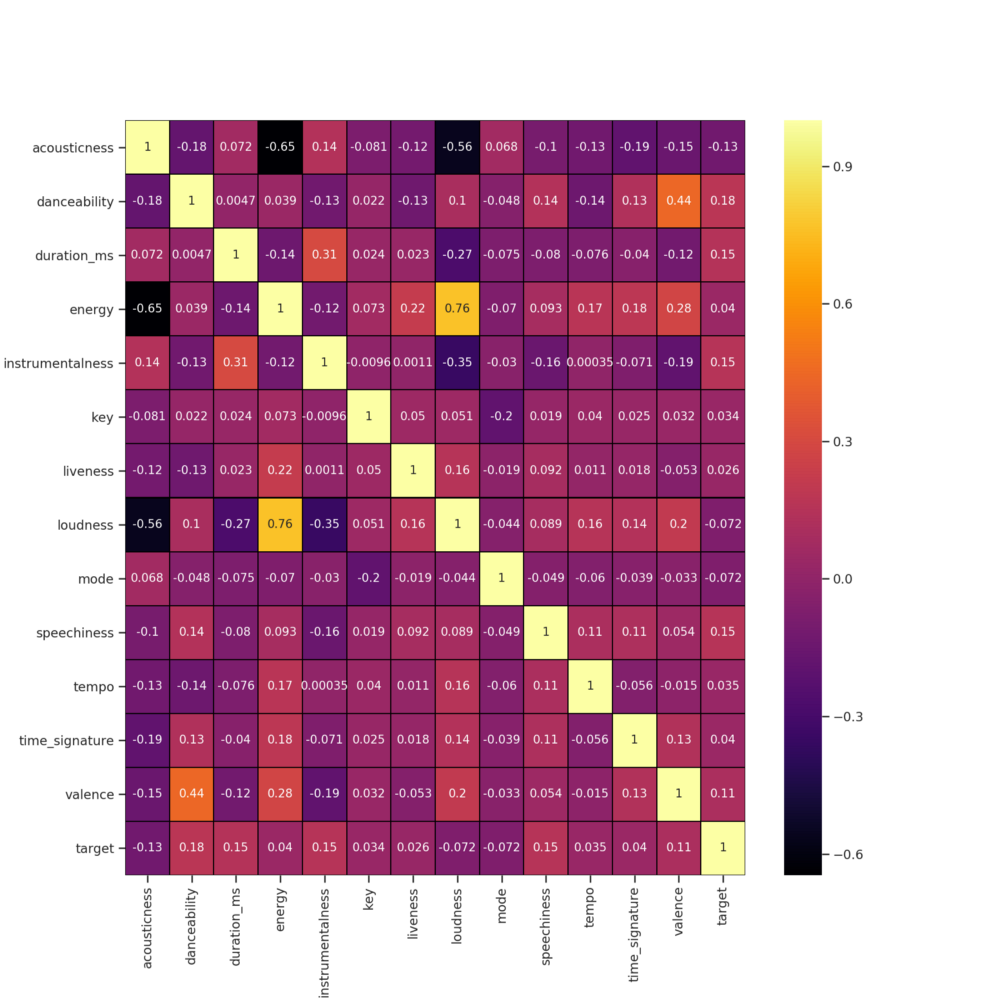
De acordo com a tabela de graus de correlações acima, podemos fazer as seguintes considerações considerando as relações mais expressivas:
- A feature acousticness possui uma correlação moderada e negativa em relação as features energy e loudness,
- A feature energy possui uma correlação muito forte e positiva em relação a loudness,
- A feature valence possui uma baixa correlação em relação a danceability
Gráficos de Dispersão
Vamos visualizar a dispersão dos dados mais interessantes (que possuem correlações mais relevantes) de acordo com o heatmap acima:
# Configuração do primeiro panel de gráficos de dispersão
axis = ['ax0','ax1','ax2']
features = [['acousticness','energy'],['acousticness','loudness'],['acousticness','danceability']]
colors = ['g', 'b','#bee000']
titles = ['Acousticness x Energy', 'Acousticness x Loudness', 'Acousticness x Danceability']
plotarDispersoesRegressao(1,3,axis,features,colors,titles)Gráfico de dispersão de Acousticness em relação a Energy, Loudness e Danceability
# Configuração do primeiro panel de gráficos de dispersão
axis = ['ax0','ax1','ax2']
features = [['acousticness','energy'],['acousticness','loudness'],['acousticness','danceability']]
colors = ['g', 'b','#bee000']
titles = ['Acousticness x Energy', 'Acousticness x Loudness', 'Acousticness x Danceability']
plotarDispersoesRegressao(1,3,axis,features,colors,titles)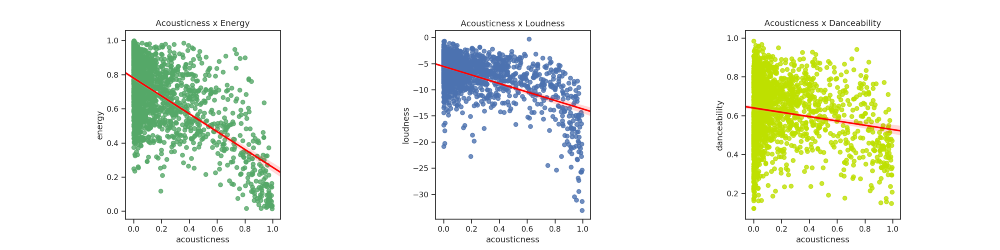
Pode-se perceber que há relações negativas relevantes: As faixas com maior possibilidade de serem acústicas tem a tendência de possuir menor energia, uma menor sonoridade e menor tendência de serem dançantes.
Gráfico de dispersão de Energy em relação a Loudness e Valence
# Configuração do primeiro panel de gráficos de dispersão
axis = ['ax0','ax1']
features = [['energy','loudness'],['energy','valence']]
colors = ['#48d66c', '#bd36d8']
titles = ['Energy x Loudness', 'Energy x Valence']
plotarDispersoesRegressao(1, 2, axis,features,colors,titles)
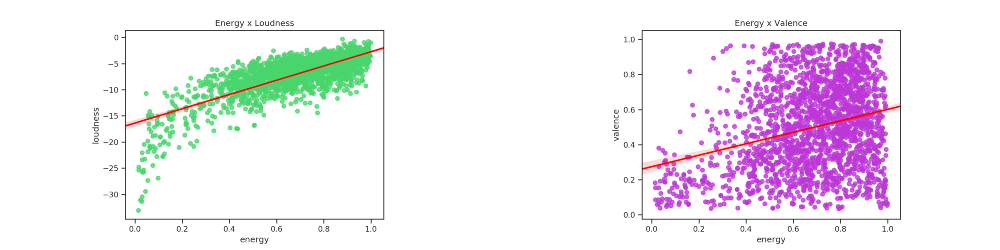
Observa-se que há relações positivas relevantes quanto a Loudness e, uma pouco influente, porém positiva em relação a Valence: As faixas com maior energia tem a tendência de possuir maior volume em decibéis, o que faz todo o sentido! Quanto a valência, há uma leve inclinação positiva, porém considerável quando a música possui mais energia.
Gráfico de dispersão de Valence em relação a Danceability e Instrumentalness
# Configuração do primeiro panel de gráficos de dispersão
axis = ['ax0','ax1']
features = [['valence','danceability'],['valence','instrumentalness']]
colors = ['#5d00e0', '#be00e0']
titles = ['Valence x Danceability', 'Valence x Instrumentalness']
plotarDispersoesRegressao(1, 2, axis,features,colors,titles)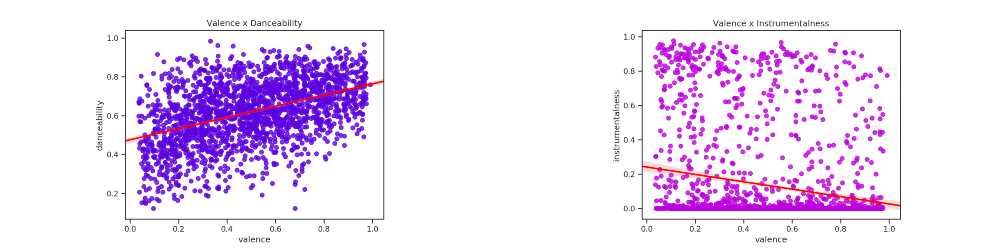
Percebe-se que há relações positivas relevantes quanto a Valence e Danceability, o que faz sentido, geralmente músicas mais positivas tem a tendência de serem mais dançantes. Quanto a Instrumentalness, há uma inclinação negativa, porém há várias faixas fora desse padrão.
Gráfico de dispersão de Tempo em relação a Speachiness e Valency
# Configuração do primeiro panel de gráficos de dispersão
axis = ['ax0','ax1']
features = [['tempo','speechiness'],['tempo','valence']]
colors = ['#bee000', '#00e0d1']
titles = ['Tempo x Speechiness', 'Tempo x Valence']
plotarDispersoesRegressao(1, 2, axis,features,colors,titles)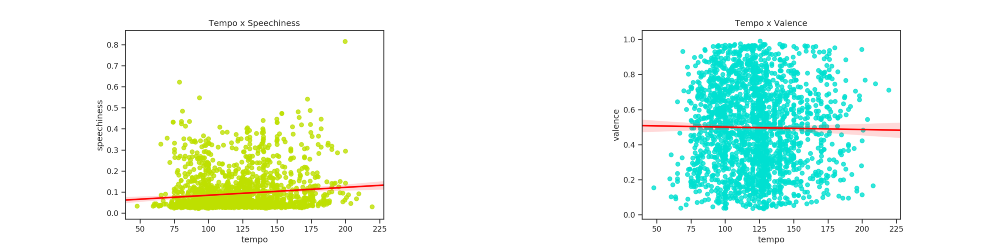
O tempo em relação a Speechiness possui uma leve relação positiva, indicando que há uma leve tendência de aumento dos 75 até os 175 RPM. Quanto a valência, percebe-se que está bem distribuída, impedindo a verificação de tendência de aumento ou não.
Gráficos em relação ao gosto musical do usuário
Discretização dos dados para identificar as preferências musicais do usuário (0 — Não gosta da música, 1 — Gosta da música ):
labels = pd.cut(dataset['target'],2,labels=['Não gosta','Gosta'])
dataset['labels'] = labelsSeparação das features a serem usadas para a criação do painel pairplot:
features = ['tempo', 'acousticness', 'danceability', 'valence','speechiness', 'labels']Criação do pairplot para visualizar as correlações com as preferências do usuário:
%matplotlib inline
sns.set(style="ticks", color_codes=True)
sns.pairplot(dataset[features], kind="reg", hue="labels")
plt.savefig("imagens/test_rasterization.png", dpi=150)
plt.show()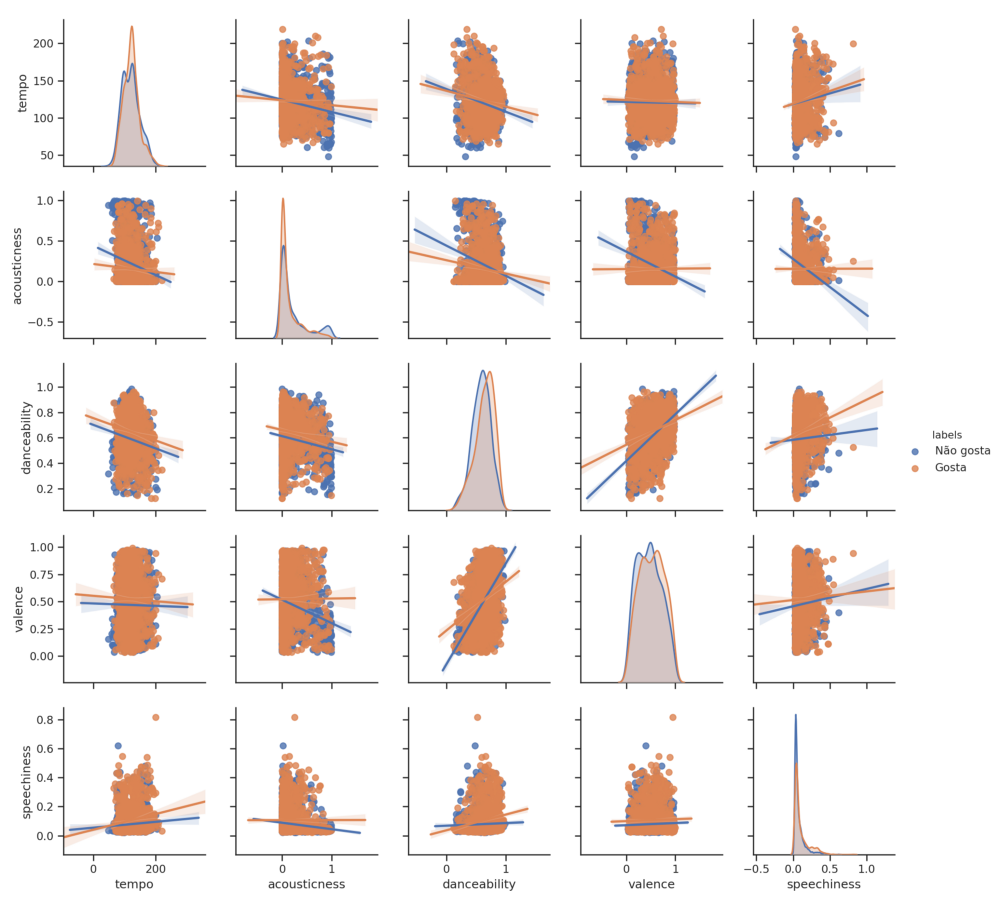
Na cor salmão podemos visualizar as preferências do usuário e sua respectiva linha de regressão, na cor azul temos as músicas que não são as preferidas do usuário e sua linha de regressão. Através dos gráficos e das análises realizadas, podemos concluir que as músicas aprovadas pelo usuário e as não aprovadas possuem em geral uma correlação parecida, variando em alguns aspectos como na correlação entre acousticness e speechiness e acoustic e valence.
No próximo artigo, será realizada a análise dos dados e reconhecimentos dos padrões, para a classificação e análise de regressão linear com o intuito de estimar através de algumas das características do dataset a preferência musical do usuário.


