
Imagine que você possua um conjunto de arquivos csv. No momento que você coleta os dados da fonte existe a possibilidade de ‘repousá-los’ em uma zona intermediária conhecida como “staging area” — onde, basicamente realizamos uma cópia da nossa base de dados evitando acessar diretamente os dados na fonte.
Em cenários mais simples (como o que abordaremos aqui), não precisamos nos preocupar tanto com algumas questões que envolvem armazenamento, segurança ou performance. Nosso intuito é mostrar a possibilidade de tornar o nosso trabalho mais profissional utilizando um dos bancos de dados relacionais mais populares: o SQLite.
SQLITE
De acordo com a página oficial, o SQLite pode ser definido como um engine de banco de dados livre para uso. Uma das características mais notáveis deste engine é a sua simplicidade e leveza — sendo implementado em grande parte dos smartphones. Além disso, o SQLite lê e grava diretamente no disco e pode ser executado de forma independente de SO.
CSV
Por outro lado, apesar da popularidade, os arquivos CSVs possuem algumas limitações. Diferentemente de uma planilha excel, os CSVs armazenam arquivos em uma única sheet, utilizando algum separador para identificar cada campo. Para datasets simples, provavelmente você não terá problemas. No entanto, a medida que a complexidade dos dados aumenta pode ser necessário pensar em uma solução mais escalável (ou melhor, no momento que você define/avalia o problema de negócio, a escalabilidade é algo que precisa ser considerada, Ok?).
NOSSO OBJETIVO
Para esta demonstração o que faremos é utilizar como input um conjunto de tabelas relacionadas que foram disponibilizadas em arquivos CSVs e mover esses dados para o SQLite utilizando as duas linguagens mais populares em ciência de dados — Python e R.
O QUE NÃO FAREMOS AQUI
- Avaliar/otimizar desempenho de queries.
- Comparar implementação entre as linguagens.
TOOLKIT
- Python : 3.6.4 — https://www.python.org/downloads/
- R: 3.5.2 — https://cran.r-project.org/bin/
- DB Browser for SQLite — https://sqlitebrowser.org/dl/
DATASETS e SCRIPTS
Os datasets e scripts desta demonstração podem ser acessados no meu Github.

Nota: caso você deseje executar os scripts (especialmente em Python) com copy/paste deste post, atente-se a indentação!
SOBRE O DATASET
O banco de dados que utilizaremos é o Sakila database. Que contém informações a respeito de locação de filmes em uma loja de DVD online. Para simplificar retiramos um subset desse BD conforme exibe a figura abaixo.
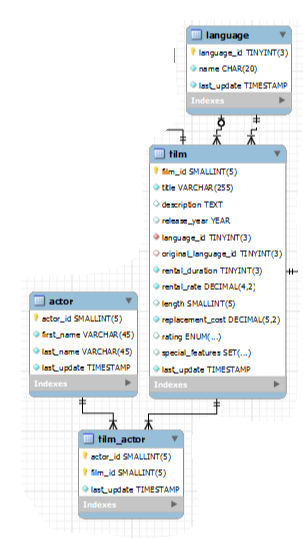
Nosso modelo tem 4 tabelas: actor, film_actor, film e language.
LET’S GO
Suponha que você solicite alguns dados ao DBA da sua empresa. Com base nisso, ele disponibiliza 4 arquivos csv com os dados que você pediu. Criaremos um script mais automatizado a fim de que não precisemos realizar muitas modificações a cada nova iteração (inserção de uma nova tabela, por exemplo).

:: Python
Primeiramente vamos ler todos arquivos csv que estão presentes em um diretório cujo nome é: sakila_data. Então, criamos uma função anônima (lambda) para varrer todos os arquivos csv e restringimos a nossa condição de busca ao diretório sakila_data aplicando a função filter e, ao final, convertermos tudo em uma lista.
# ler todos os arquivos csv do diretório e guardar em um objeto
import os
all_files = list(filter(lambda x: ‘.csv’ in x, os.listdir(‘sakila_data/’)))
Agora, podemos fazer a leitura de todos os arquivos presentes no diretório criando uma lista vazia (full_dataset) e utilizamos um loop para fazer a leitura de cada arquivo e, assim preenchermos a lista utilizando o método append.
# realizar a leitura para cada arquivo
import pandas as pd
full_dataset = []
for elem in all_files:
data = pd.read_csv(‘sakila_data/’+ elem)
full_dataset.append(data)
Vamos criar uma conexão com o SQLite. Observe que o único parâmetro que precisamos passar é o nome do banco que será criado.
import sqlite3
# estabelecendo a conexão e criando o banco
con = sqlite3.connect(‘py_database_films.db’)
Para obter o nome das nossas tabelas utilizamos como referência o nome dos arquivos csv. O método splitext é o responsável por separar entre o nome do arquivo e a extensão. O valor cujo índice é [0] garante que pegaremos apenas a primeira coluna com os nomes dos arquivos.
# obtendo os nomes das tabelas
table_names = [os.path.splitext(elem)[0] for elem in all_files]
Em seguida, obteremos os campos de todas as tabelas. Dentro do laço, coletamos a primeira linha (cabeçalho) e armazenamos em columnNames finalizando com umappend na lista table_fields.
# obtendo os campos de todas as tabelas
table_fields = []
for i in range(0,len(table_names))::
columnNames = list(full_dataset[i].head(0))
table_fields.append(columnNames)
Antes da criação e inserção de dados, é necessário definirmos um cursor para interagir com os registros do BD.
cur = con.cursor()
Nesse momento, criaremos as tabelas dentro do SQlite. Para cada elemento das minhas tabelas do csv, executamos uma query para criação das tabelas. Passando para a função execute() o nome da tabela(table_names[item])bem como os campos que as compõe utilizando o separador vírgula (‘,’.join(table_fields[item])).
# criando as tabelas no SQLite
for item in range(0,len(table_names)):
cur.execute(“””CREATE TABLE IF NOT EXISTS “”” + table_names[item] + “””(“”” + ‘,’.join(table_fields[item])+”””)”””)
A última etapa é realizar a carga dos registros em todas as tabelas. Isso será feito por um laço de repetição que percorre cada tabela realizando a carga dos registros e em seguida grava a execução utilizando o commit().
# Varre todas as tabelas e para cada uma é realizado a inserção dos dados for ind in range(0, len(table_names)):
query = “””INSERT INTO “”” + str(table_names[ind]) + “””(“”” + ‘,’.join(table_fields[ind]) + “””) VALUES (“””+ ‘,’.join(map(str,’?’*len(full_dataset[ind].columns))) +”””)”””
full_dataset[ind] = full_dataset[ind].astype(str)
for i in range(0, len(full_dataset[ind])):
insert_register = tuple(full_dataset[ind].iloc[i])
cur.execute(query, insert_register)
con.commit()

:: R
Uma outra opção, é utilizar a linguagem R para transportar os seus arquivos csv para o SQLite. Utilizaremos 2 bibliotecas: readr para fazer leitura dos arquivos e RSQLite para trazer o SQLite para dentro do ambiente R. A primeira biblioteca não é obrigatória, porém é mais otimizada para coletar os dados. Em seguida, utilizamos a função lapply queaplica uma função (read_csv) e faz a leitura dos arquivos csv que foram listados no diretório corrente (sakila_data).
# movendo dados de um CSV para um SQLite
setwd(“sakila_data/”)
library(readr)
# buscar todos os arquivos csv do diretório
full_dataset <- lapply(list.files(pattern=”*.csv”), read_csv)
Agora podemos conectar ao SQLite. Passamos o driver de conexão ao dbDriver e criamos o banco atribuindo um nome (r_database_films.db). Nomearemos nossas tabelas com o nome dos arquivos utilizando a função gsub (para todos os arquivos csv presente no diretório (dir(pattern = “*.csv”)) substitua por vazio onde encontrar csv).
# driver de conexão
drv <- dbDriver(“SQLite”)
con <- dbConnect(drv, dbname = “r_database_films.db”)
# nomes dos arquivos
table_names <- c(gsub(“[.]csv”, “”, dir(pattern = “*.csv”)))
Finalizamos com a gravação dos registros no banco de dados. A função dbWriteTable espera que você passe como argumento: a conexão, o nome da tabela eo dataframe — que contém todos os registros da nossa fonte.
# para cada linha do dataset faça a inserção no banco
for (row in seq_along(full_dataset)){
dbWriteTable(con, table_names[row], full_dataset[[row]], row.names = FALSE)
}
:: DB Browser for SQLite
Você pode abrir o arquivo que criamos — py_database_films e/ou r_database_films. Para isso, abra o DB Browser for SQLite, procure pelo arquivo desejado. Procure pela aba “Executar SQL”. E fique a vontade para explorar os dados no SQLite. Por exemplo, você pode listar todos os atores e fazer um join entre duas tabelas, conforme mostramos abaixo:
- SELECT * FROM film_actor;
- SELECT * FROM film f JOIN film_actor fa on f.film_id = fa.film_id;
CONCLUSÃO

Perceba que a utilização de um banco de dados como SQLite permite que possamos trabalhar com os relacionamentos utilizando comandos SQL tornando o nosso trabalho mais profissional. Não a toa o SQLite é um dos bancos de dados mais comuns devido a sua leveza e simplicidade.
É claro que nem sempre você receberá um dataset com id’s que relacionam as tabelas. Nesses casos, será necessário modelar ou construir esses relacionamentos antes de movê-lo a um BD relacional. De qualquer forma, o processo é o mesmo— você busca os dados, realiza alguma etapa de transformação e limpeza e depois “empurra” os dados pré-processados para uma stage.
Espero que ter contribuído com seu conhecimento. Grande abraço!
Fonte: Próprio Autor.
Post: https://medium.com/@fernando.gama/movendo-arquivos-csv-para-o-sqlite-com-python-e-r-8a2b40f3cb66


Seja o primeiro a comentar